SLO — From Nothing to… Production
In the last months, I’ve started learning and reading more about Service Level Objectives (SLO). I will not go into many details about what the SLOs are, as you can find more detailed explanations in the books that I mention in the next section.
My main focus is on how I educated myself about SLOs and how applied this to my organization. My biggest learning is that the SLO mindset is definitely a marathon, so be prepared for it and pace yourself! Personally, I found it a very educative and fun process and I hope some of the learnings will be useful for someone.
Prepare yourself
I spent around 4 months preparing myself and studying before I even considered starting the SLO journey. When I first read the SRE books, I understood what is an SLO and that is important but that was it. I had to read part of the books again to get a better understanding of all the other concepts that come with it, like SLI, error budgets, burn rates, etc…
The books that I read and you are probably already familiar with are:
- Site Reliability Engineering and how Google does it!
- The Site Reliability Workbook and practical ways to implement SRE.
- Implementing Service Level Objectives by Alex Hidalgo with tons of details on how you implement SLOs to your organization.
During all the process (end even now) I keep coming back to the books to refresh my memory regarding a concept, etc… I found it very practical to have these books on Kindle where I can search and read notes again and again!
Also, as I wanted to learn more practical concepts around SLOs I completed the SRE Measuring and Managing Reliability course. I found the course very useful for practical things like SLI vs SLO (yeah it was not that clear at the start for me), how I can do risk analysis, etc.. . I highly recommend it!
The Art of SLOs workshop has lots of good material that you can read and practice on SLOs (even on your own). Check the provided presentations and notes.
Even after all this preparation, I was thinking: “Ok this sounds even cooler now but where do we start from?!”
Where to start
Every organization has different forums where you can propose new things. I followed one very simple approach. I wrote a three pages proposal (it can be in an RFC format or not). After I wrote it down I shared the document with the engineering and product leadership and gave them about 10 days to leave comments/etc.. and discuss async about it.
The next step was to arrange a meeting where we can go through the proposal and answer any other questions. Your goal should be to take the “thumbs up” to go on with the SLOs and their importance, so make sure you will define some clear actions on how you think this will move forward. My proposal had the following sections:
Explain what is the problem we are trying to solve
I started by mentioning how SLOs will help us as an organization. Mention that reliability is the most important feature of any system. And expand on how SLOs can help to have more educative discussions about reliability, work prioritization by using data that matters for our users.
Summarise the key concepts
Consider that your audience may never heard about SLOs. Explain what SLOs, SLIs, and error budgets are. Make sure you include an example of these concepts.
I found that the error budget was the concept that I had to explain more and it was not very clear to everyone what it means. I think the word “budget” and “who manages” this budget needs to be explained. For example, mention that the product teams will still own their teams’ time/roadmap but now they have to take into account this as well. Mention if we run out of error budget we will possibly have unhappy users; to understand more the concept and the importance of it.
How SLO translates to something useful that the organization can understand
Most of the organizations and stakeholders understand and care about Service Level Agreements (SLAs). Explain how SLOs can be an important internal tracking target that is tougher than your SLA. Also, mention how we can use the SLOs to offer better SLAs than “service uptime” if we are asked. This will vary from organization to organization, so make sure you adapt this.
Give an example of how this work
I think it is important to have an example of how you are visioning SLOs to work in practice. Explain how SRE and Product teams will work together to identify user journeys, how you will set an SLO (give an example SLO), and then explain what happens if you under or over-performing in an X days window. The more details the better here and expect a lot of questions that you will probably don’t have the answers to them yet, but come back to them later.
Suggest some actions
In the last section mention some actions and how you are thinking to roll this out to the organization. In my case, I proposed that SRE will take full ownership to set up a “framework” (docs, services, processes, etc…) that will cover everything that is needed to start having SLOs. Also, mention how you believe that Product teams will take full ownership of SLOs as we all learn more about it and adopt the framework.
Take ownership and be an SLO advocate
After your proposal is (hopefully) approved, prepare to be an SLO advocate and to over-communicate things about SLOs. It will be a new concept and way of thinking for most of your department. It is important that you are not alone in this journey; so make sure you get onboard other SREs and Engineers/Product Managers.
We did some of the following things to take everyone on board in the “SLO Journey”, obviously these will be different for your organization but you can use most of them!
- Lightning talks about what SLO/SLI are, why they are important, etc…
- 45 minutes talk to the Product and Engineering department using the Art of SLOs slides. You will probably need to adapt the slides but it's a good start.
- All hands 5-minute slot to explain how SLOs are linked to user happiness at a very high level, and also how they are not SLAs but they can be used for better SLAs.
- When you write documentation or you make any progress about something related to SLO share it with the department. This is important to not just show progress but to also take everyone aboard in the journey.
Build the framework
As I mentioned in the proposal before, the initial action was for us (SREs) to build the framework while we learn more things about SLOs. And what I mean by the framework is to write documentation, find where you will display your SLOs, how you can create and use SLIs, how you can do alerting, how you will work with product teams, and more!
You don’t need to answer all these questions at once, and you will iterate a lot as you learn more.
Documentation:
We decided to have a single GitHub repository where we will have all our documentation about “reliability”. This is a good start to have everything in one place. Some of the documentation that we wrote can be found in more detail on the internet but we wanted to have something that everyone can check internally quickly. Some of the docs that we keep in this repo are:
- What is an SLI and what are the different types
- A template for an SLO document, we used a modified version from the books that I mentioned in the first section.
- All SLO documents that are under review or approved, one SLO document per service.
- Q&A docs about “math” needed to calculate things, or what is freeze period, etc..
- Our approved Error budget policy, we decided to start with one error budget policy for all the SLOs and review in 6 months. Try to keep things simple at the start as you all learning. To get this approved, we followed the same approach with the initial proposal. Try to adapt this policy to something realistic for your organization. SLOs are all about iterating and constantly learning.
Dashboard:
The next thing we have to figure out was where are we going to display our SLO dashboards. Your organization probably already has a solution for dashboards in place, try to use the one you already have to move faster. In our case, we use Grafana so we had already a good tool that we could use.
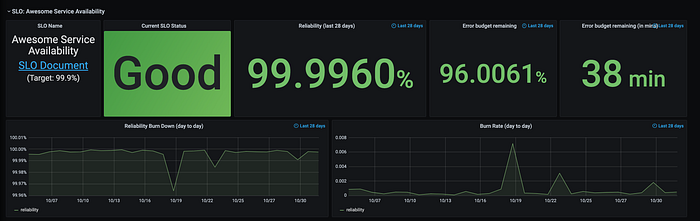
After lots of research and “inspiration” from the books mentioned earlier, we ended up in a dashboard that some of the core parts are:
- A panel where you can link back to the SLO Document
- GOOD/BAD panel to know with a glance of an eye how the SLO is performing
- Current reliability and error budget remaining (for your window)
- And two panels that explain day to day the reliability and the burn rate.
Example dashboard:
SLIs:
Obviously, you can’t have good SLOs if you don't have good SLIs. We reviewed all the monitoring tools that we use to see how they can use them for SLIs. You will find that most of the providers are not offering a good interface for SLIs but most of them are offering APIs that you can consume. And as not everyone is using Prometheus (including us) we decided to build a service to provide us the SLIs that we need.
The service that we build is very simplistic. We were generating events using a cron-scheduler based on how often we want to pull an SLI entry, eg every 10 secs or 60 secs. And then a worker was consuming this event and querying a data source to create the SLI entry. Data sources can be anything from NewRelic and Datadog to your Log Server and Database. The idea is that the data that we need exist in these data sources but not in a good SLI format.
After we had the SLI entry for the time period we are pushing this information to AWS Cloudwatch, using their Custom Metrics API to create our SLIs. And this is it, we can consume these metrics from Grafana or anything else that can integrate with AWS Cloudwatch. This way we achieved a clean and consistent interface or our SLIs.
I will write up more about this service in a future post. But the important thing is to review your existing tools and try to use them before you buy or build something new.
Alerting:
So, we have our SLOs and our SLIs but how are we going to alert on them! SLOs without alerting using Burn Rates are not really complete even though it's a good start. In our case, it was very easy to do that as we have our SLIs that cover GoodEvents or BadEvents, and ValidEvents already as a Custom Metric on AWS Cloudwatch. So we used AWS Cloudwatch Alarms where we can combine for example the GoodEvents and ValidEvents metrics to calculate the Burn Rate. I will not go into much detail on these calculations as you can find then in the already mentioned SRE books
Everything in this “SLO framework” can be automated and managed by IaaC tools/etc… The reason behind this is to have a universal and easy way to introduce a new SLO.
We are very aware that we’ll probably change our “framework” but we wanted to use tools that we are already familiar with and improve it later based on our needs.
Summary
Bringing SLOs to an organization can be very challenging but if you are well prepared you can get it done. The main things for me are to get people onboard and iterate relentlessly not just in the SLO framework but also to the SLO/SLI itself. I hope you will learn something from my experience!
Stay Reliable!
